SQLFlow Overall Design
What is SQLFlow
SQLFlow is a bridge that connects a SQL engine, for example, MySQL, Hive, SparkSQL, Oracle, or SQL Server, with machine learning toolkits like TensorFlow. SQLFlow extends the SQL syntax to enable model training and inference.
Related Work
We could write simple machine learning prediction (or scoring) algorithms in SQL using operators like DOT_PRODUCT. However, this requires copy-n-pasting model parameters from the training program into SQL statements.
Some proprietary SQL engines provide extensions to support machine learning.
Microsoft SQL Server
Microsoft SQL Server has the machine learning service that runs machine learning programs in R or Python as an external script:
CREATE PROCEDURE generate_linear_model
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'lrmodel <- rxLinMod(formula = distance ~ speed, data = CarsData);
trained_model <- data.frame(payload = as.raw(serialize(lrmodel, connection=NULL)));'
, @input_data_1 = N'SELECT [speed], [distance] FROM CarSpeed'
, @input_data_1_name = N'CarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model varbinary(max)));
END;
A challenge to the users is that they need to know not only SQL but also R or Python, and they must be capable of writing machine learning programs in R or Python.
Teradata SQL for DL
Teradata also provides a RESTful service, which is callable from the extended SQL SELECT syntax.
SELECT * FROM deep_learning_scorer(
ON (SELECT * FROM cc_data LIMIT 100)
URL('http://localhost:8000/api/v1/request')
ModelName('cc')
ModelVersion('1')
RequestType('predict')
columns('v1', 'v2', ..., 'amount')
)
The above syntax couples the deployment of the service (the URL in the above SQL statement) with the algorithm.
Google BigQuery
Google BigQuery enables machine learning in SQL by introducing the CREATE MODEL statement.
CREATE MODEL dataset.model_name
OPTIONS(model_type='linear_reg', input_label_cols=['input_label'])
AS SELECT * FROM input_table;
Currently, BigQuery only supports two simple models: linear regression and logistic regression.
Design Goal
None of the above meets our requirement.
First of all, we want to build an open source software. Also, we want it to be extensible:
-
We want it extensible to many SQL engines, instead of targeting any one of them. Therefore, we don’t want to build our syntax extension on top of user-defined functions (UDFs); otherwise, we’d have to implement them for each SQL engine.
-
We want the system extensible to support sophisticated machine learning models and toolkits, including TensorFlow for deep learning and xgboost for trees.
Another challenge is that we want SQLFlow to be flexible enough to configure and run cutting-edge algorithms, including specifying feature crosses. At the same time, we want SQLFlow easy to learn – at least, no Python or R code embedded in the SQL statements, and integrate hyperparameter estimation.
We understand that a key to address the above challenges is the syntax of the SQL extension. To craft a highly-effective and easy-to-learn syntax, we need user feedback and fast iteration. Therefore, we’d start from a prototype that supports only MySQL and TensorFlow. We plan to support more SQL engines and machine learning toolkits later.
Design Decisions
As the beginning of the iteration, we propose an extension to the SQL SELECT statement. We are not going a new statement way like that BigQuery provides CREATE MODEL, because we want to maintain a loose couple between our system and the underlying SQL engine, and we cannot create the new data type for the SQL engine, like CREATE MODEL requires.
We highly appreciate the work of TensorFlow Estimator, a high-level API for deep learning. The basic idea behind Estimator is to implement each deep learning model, and related training/testing/evaluating algorithms as a Python class derived from tf.estimator.Estimator. As we want to keep our SQL syntax simple, we would make the system extensible by calling estimators contributed by machine learning experts and written in Python.
The SQL syntax must allow users to set Estimator attributes (parameters of the Python class’ constructor, and those of train, evaluate, or predict). Users can choose to use default values. We have a plan to integrate our hyperparameter estimation research into the system to optimize the default values.
Though estimators derived from tf.estimator.Estimator run algorithms as TensorFlow graphs; SQLFlow doesn’t restrict that the underlying machine learning toolkit has to be TensorFlow. Indeed, as long as an estimator provides methods of train, evaluate, and predict, SQLFlow doesn’t care if it calls TensorFlow or xgboost. Precisely, what SQLFlow expect is an interface like the following:
class AnEstimatorClass:
__init__(self, **kwargs)
train(self, **kwargs)
evaluate(self, **kwargs)
predict(self, **kwargs)
We also want to reuse the feature columns API from Estimator, which allows users to columns of tables in a SQL engine to features to the model.
Extended SQL Syntax
Again, just as the beginning of the iteration, we propose the syntax for training as
SELECT * FROM kaggle_credit_fraud_training_data
LIMIT 1000
TO TRAIN DNNClassifier /* a pre-defined TensorFlow estimator, tf.estimator.DNNClassifier */
WITH layers=[100, 200], /* a parameter of the Estimator class constructor */
train.batch_size = 8 /* a parameter of the Estimator.train method */
COLUMN *, /* all columns as raw features */
cross(v1, v9, v28) /* plus a derived (crossed) column */
LABEL class
INTO sqlflow_models.my_model_table; /* saves trained model parameters and features into a table */
We see the redundancy of * in two clauses: SELECT and COLUMN. The following alternative can avoid the redundancy, but cannot specify the label.
SELECT * /* raw features or the label? */
cross(v1, v9, v28) /* derived features */
FROM kaggle_credit_fraud_training_data
Please be aware that we save the trained models into tables, instead of a variable maintained by the underlying SQL engine. To invent a new variable type to hold trained models, we’d make our system tightly integrated with the SQL engine, and harms the extensibility to other engines.
The result table should include the following information:
- The estimator name, e.g.,
DNNClassifierin this case. - Estimator attributes, e.g.,
layerandtrain.batch_size. - The feature mapping, e.g.,
*andcross(v1, v9, v28).
Similarly, to infer the class (fraud or regular), we could
SELECT * FROM kaggle_credit_fraud_development_data
TO PREDICT kaggle_credit_fraud_development_data.class
USING sqlflow_models.my_model_table;
System Architecture
A Conceptual Overview
In the prototype, we use the following architecture:
SQL statement -> our SQL parser --standard SQL-> MySQL
\-extended SQL-> code generator -> execution engine
In the prototype, the code generator generates a Python program that trains or predicts. In either case,
- it retrieves the data from MySQL via MySQL Connector Python API,
- optionally, retrieves the model from MySQL,
- trains the model or predicts using the trained model by calling the user specified TensorFlow estimator,
- and writes the trained model or prediction results into a table.
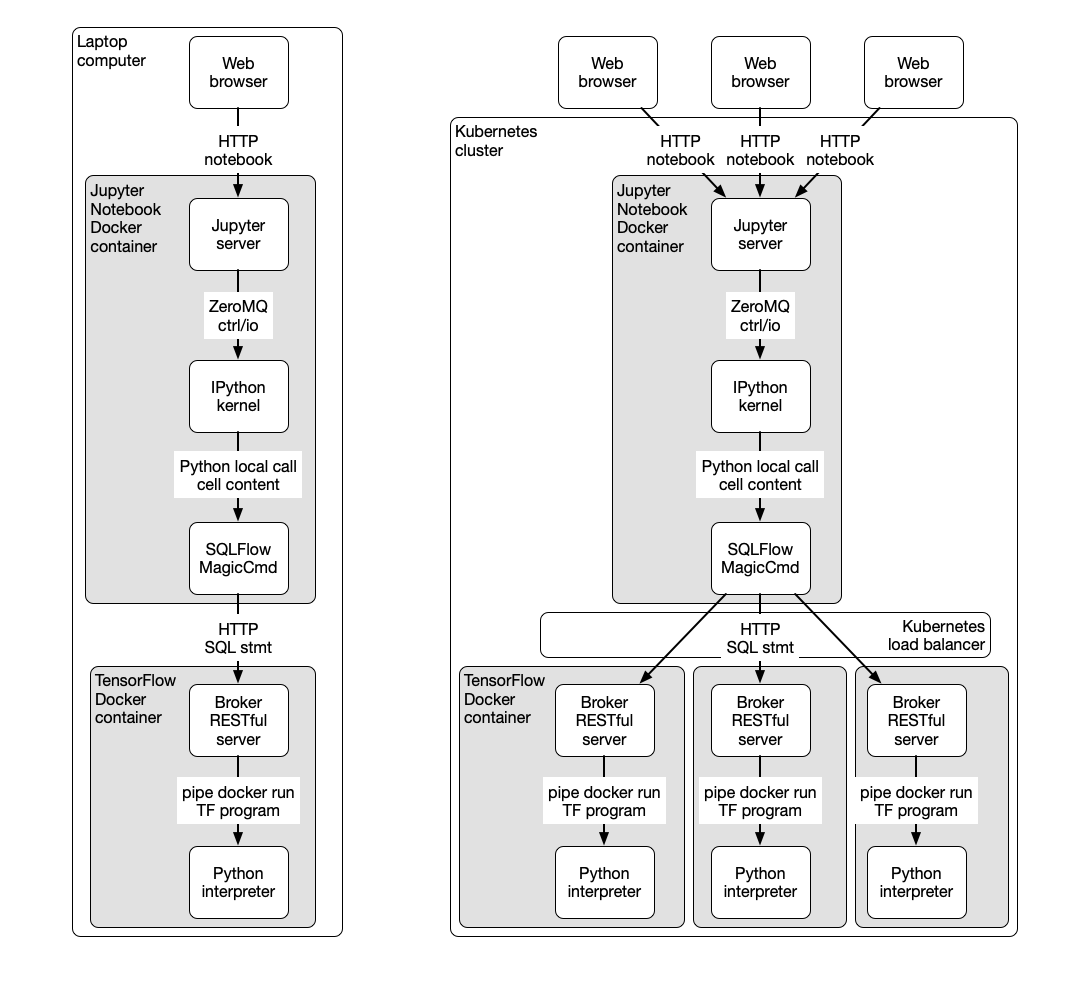
Working with Jupyter Notebook and Kubernetes
The following figure shows the system components and their runtime environment. The left part shows how to run the system on a PC/laptop, and the right part shows how to run it on a Kubernetes cluster.