Data IO Pipeline Design
Data IO pipeline for ElasticDL involves reading data from RecordIO file or ODPS table, making data generator for tf.data.Dataset and parsing features and labels by dataset_fn user defined (see the following figure).
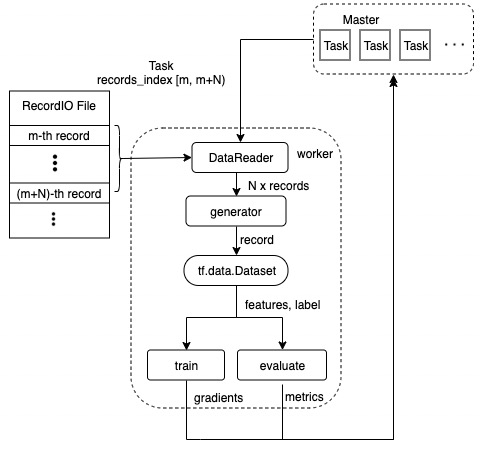
Let’s take the RecordIO file for example. After a worker is launched, it will send request to get tasks from the master. Each task contains the record index range [m, m+N) which can locate records in RecordIO file. DataReader reads N records from RecordIO file by task index range and yields each record to create a generator. Then the worker will perform the following steps to consume the record data from the generator:
- Create a dataset by tf.data.Dataset.from_generator.
- Convert dataset by dataset_fn user defined to generate features and labels.
- Calculate gradients of trainable variables for the training task and predictions of samples for the evaluation task.
- Send calculation result to the master.
- Send task execution status to the master after processing all records of this task.