Serving Design
Background
Model serving is an essential part in an end-to-end machine learning lifecycle. Publishing the trained model as a service in production can make it valuable in the real world. In this article, we focus on how to save the model trained in ElasticDL for serving.
SavedModel is the universal file format for TensorFlow models. It’s language neutral and can be loaded by multiple frameworks (such as TFServing, TFLite, TensorFlow.js and so on). We choose to export the ElasticDL model to the SavedModel format. In this way, we can leverage various mature solutions to serving our model in different scenarios.
The model size can vary from several kilobytes to several terabytes. Exporting to SavedModel can’t apply to all the scenarios. We divide the model size into two categories: Small or medium size and large size. The small or medium size model can be loaded by a process, but the latter cannot fit in a single process. Training and serving strategies are different between these two cases. The following table describes the choices of serving strategy considering model size and several training strategies:
| Master Central Storage | AllReduce | Parameter Server | |
|---|---|---|---|
| Small or Medium Size Model | SavedModel | SavedModel | SavedModel |
| Large Size Model | N/A | N/A | Distributed Parameter Server for Serving |
We consider three main training strategies of ElasticDL. 1) Master central storage strategy (implemented): The master node loads the entire model. Workers pull the model from the master while processing each minibatch of data. 2) AllReduce strategy (planning): It mainly supports synchronized training. Each worker loads a replica of the entire model. AllReduce aggregates gradients across all workers and publishes them to each worker. 3) Parameter server strategy (in progress): We store the model variables on the parameter servers. All the workers pull the variables as needed from the parameter server and execute computation.
Small or medium size model A single serving process can load the entire model into memory. No matter which training strategy to choose, we will export the model to the SavedModel format. For master central storage and AllReduce strategy, each worker has a replica of the entire model and then export it directly. For parameter server strategy, the model contains unsaveable elasticdl.layers.Embedding layer and the variables are stored in the PS. We will use the process in the section below to export the model. And then we can deploy it using the existed serving frameworks like TFServing. We focus on this case in this article.
Large size model A single serving process will run out of memory while loading the model. We partition the model variables into multiple shards, store them in distributed parameter server for serving. The inference engine will execute the serving graph, query the variable values from the distributed parameter server as needed and finish the calculation. It’s necessary to upgrade the serving framework to support this. We will discuss this case in a separate design in the next step.
In this article, we want to achieve these three goals in ElasticDL:
- Guarantee consistency between training and serving for input data preprocessing.
- Export the model with elasticdl.layers.Embedding to SavedModel.
- Execute task to save model with fault-tolerance.
Consistent input data preprocessing for training and serving
ElasticDL is a distributed deep learning framework based on TensorFlow 2.0 eager execution. In ElasticDL, we use tf.data.Dataset to create input pipeline for training. The recommended way to preprocess data from tf.data.Dataset is to use feature columns in TensorFlow. What’s more, tf.saved_model.save will save the defined feature columns with the model. So tf-serving will use the same preprocessing logic with training to make inference.
Define a Keras model with feature columns:
def get_feature_columns():
age = tf.feature_column.numeric_column("age", dtype=tf.int64)
education = tf.feature_column.categorical_column_with_hash_bucket(
'education', hash_bucket_size=4)
education_one_hot = tf.feature_column.indicator_column(education)
return [age, education_one_hot]
def get_input_layer():
input_layers = {}
input_layers['age'] = tf.keras.layers.Input(name='age', shape=(1,), dtype=tf.int64)
input_layers['education'] = tf.keras.layers.Input(name='education', shape=(1,), dtype=tf.string)
return input_layers
def custom_model(feature_columns):
input_layers = get_input_layer()
dense_feature = tf.keras.layers.DenseFeatures(feature_columns=feat_cols)(input_layers)
dense = tf.keras.layers.Dense(10, activation='relu')(dense_feature)
dense = tf.keras.layers.Dense(1, activation='sigmoid')(dense)
return tf.keras.models.Model(inputs=input_layers, outputs=dense)
Although all feature columns in TensorFlow can be used in ElasticDL, tf.feature_column.embedding_column is not recommended in ElasticDL at present. Because the embedding_column has a variable containing a large embedding table. In eager execution the model must get all the embedding parameters to train. It will bring a large inter-process communication overhead.
Export the model with elasticdl.layers.Embedding to SavedModel
Using native Keras layers to define a model is more user-friendly than using custom layers in ElasticDL. However, it is inefficient to train a model with tf.keras.layers.Embedding. When the model executes the forward-pass computation for each mini-batch, it must get all embedding parameters from the parameter server (PS) even if the mini-batch only contains several embedding ids. So, the elasticdl.layers.Embedding is designed to improve the training efficiency in ElasticDL. Considering user-friendliness and training efficiency, we need to define a model with tf.keras.layers.Embedding and train the model with elasticdl.layers.Embedding. For the Sequential model and the Functional models, we can use tf.keras.models.clone_model to replace the tf.keras.layers.Embedding with elasticdl.layers.Embedding before training starts. For subclass model, we can replace the attribute of tf.keras.layers.Embedding type with elasticdl.layers.Embedding.
def generate_train_model_for_elasticdl(model, distribute_strategy):
if distribute_strategy == 'ps':
model = replace_keras_embedding_with_edl_embedding(model)
else:
return model
def replace_keras_embedding_with_edl_embedding(model):
# replace the embedding layer for Sequential and functional API models
if isinstance(model, tf.keras.Sequential) or model._is_graph_network:
def _clone_function(layer):
if type(layer) == keras.layers.Embedding:
edl_layer = elasticdl.layers.Embedding(layer.output_dim)
return edl_layer
return layer
return keras.models.clone_model(model, clone_function=_clone_function)
else:
# replace embedding attribute for subclass model
for attr_name, attr_value in model.__dict__.items():
if type(attr_value) == keras.layers.Embedding:
setattr(model, attr_name, edl_Embedding(attr_value.output_dim))
return model
However, tf.saved_model.save cannot export the replaced model to SavedModel. Because ElasticDL.Embedding uses tf.py_function to invoke RPC to interact with the parameter server. It is not mapped to any native TensorFlow op. As a result we choose to save the origin model with native keras embedding layer, replace the embedding parameters with the trained parameters of elasticdl.layers.embedding.
SavedModel needs to generate model inputs and outputs signatures to map to TensorFlow Serving’s APIs. But, the user does not need to define inputs and outputs for sequential and subclass models. We should build model with the input dataset to generate inputs and outputs for those models before using SavedModel.
def export_saved_model_from_trained_model(model, dataset):
# change elasticdl.layers.Embedding back to keras.layers.Embedding for subclass
if type(model) == tf.keras.layers.Model and not model._is_graph_network:
model = restore_keras_embedding_for_subclass(model)
# build model to add inputs and outputs for tf-serving
if not model.inputs:
model._build_model_with_inputs(inputs=dataset, targets=None)
restore_keras_embedding_from_edl_embedding(model)
tf.saved_model.save(model, export_dir)
def restore_keras_subclass_model_def(model):
for attr_name, attr_value in model.__dict__.items():
if type(attr_value) == elasticdl.layers.Embedding:
setattr(model, attr_name, keras.layers.Embedding(attr_value.output_dim))
return model
def restore_keras_model_params(model):
for layer in model.layers:
if type(layer) == tf.keras.layers.Embedding:
embedding_params = EmbeddingService.get_all_embedding_params(layer)
layer.embeddings.assign(embedding_params)
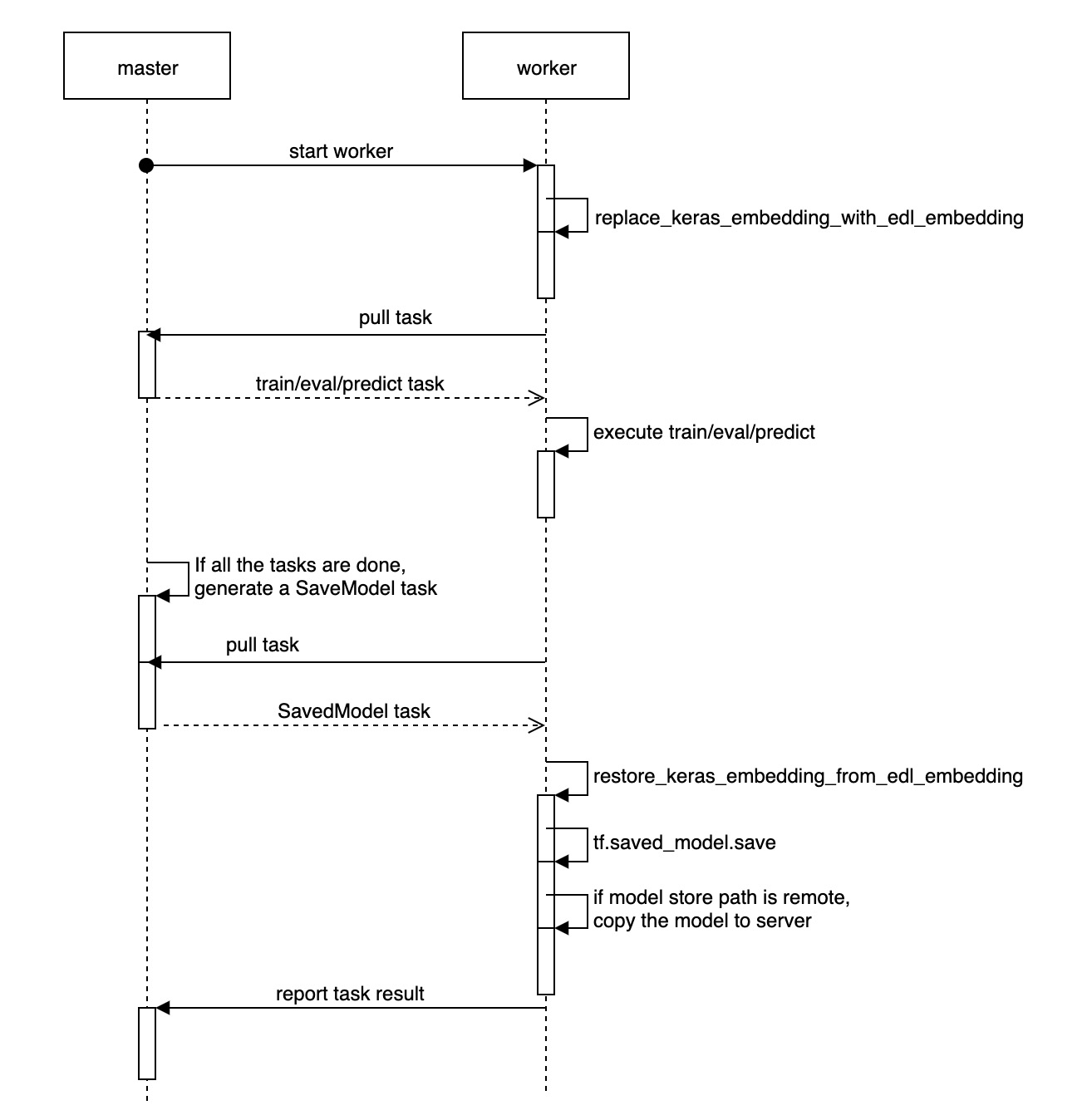
Execute task to save model with fault-tolerance
We designed the master-worker architecture and task dispatch&recover mechanism
in ElasticDL to make the job execution fault tolerant. Please check overall
design.
For model saving work, we use the same mechanism. After completing all the
training/evaluation/prediction tasks, master will generate only one SaveModel
task and insert it into the todo task queue. The first worker pulling this task
will execute the model saving process. The other workers are waiting. After
executing the SavedModel task, all the workers exit and the entire job is
completed. Please check the diagram below: