ElasticDL:基于 TensorFlow 的 Kubernetes-native 弹性分布式训练系统
TensorFlow 目前在业界得到了广泛的使用。在实际生产中, 由于参数规模和训练数据非常大,很多 TensorFlow 任务需要运行在分布式集群上。 为了提升集群的运维管理效率,工程师们会共用一个集群, 并使用集群管理系统调度分布式作业。 Kubernetes 是目前最先进的分布式操作系统,是公有云和私有云的事实工业标准。 ElasticDL 通过实现弹性调度,来提升 Kubernetes 集群上 TensorFlow 作业的研发效率和集群利用率。
Kubernetes 上运行分布式 TensorFlow 作业
目前,Kubernetes 集群上运行分布式 TensorFlow 作业主要依赖 Kubeflow 项目 提供的 Kubernetes controller —— kubeflow/tf-operator —— 这是因为 TensorFlow 不是一个 Kubernetes-native 的编程框架,自己不会调用 Kubernetes API 启动进程。类似的,很多诞生在 Kubernetes 之前的分布式编程框架 (比如 Spark)都需要一个 Kubernetes controller 来启动作业。 这类应用或者框架特定的 controller 被 CoreOS 公司的工程师们称为 Kubernetes Operator,后来演化成了行业术语。
在向 Kubernetes 集群提交作业时,kubeflow/tf-operator 会询问 Kubernetes 计划分配哪几台机器来运行一个分布式作业中的各个进程, 随后告知每个进程所有其它进程的 IP 地址和 port, 从而保证一个作业里各个进程之间互相知道对方。
为什么需要让所有进程互相知道对方呢?这是 TensorFlow 1.x ps-based distribution 方式要求的。TenosrFlow 1.x 原生的分布式训练功能让一个作业中所有进程都执行 TensorFlow 1.x runtime 程序。这些进程互相通信, 互相协调成为一个“分布式 runtime”来解释执行表示深度学习计算过程的 graph。 在开始分布式训练之初,graph 被 TensorFlow runtime 拆解成若干子 graph; 每个进程负责执行一个子 graph —— 任何一个进程被抢占(preempted) 或者失败(fail),则整个大 graph 的执行就失败了。最近随着 TensorFlow runtime 的改进,作业可以依赖剩下的进程继续执行, 不过也不会因为随后集群里出现空闲资源而增加进程的数量。 所以使用 kubeflow/tf-operator 提交 TensorFlow 分布式作业并不支持弹性调度。
Kubeflow 可以在 Kubernetes 上发挥 TensorFlow 原生的分布式计算能力, 但是因为后者并不能弹性调度运行资源,所以 Kubeflow 并不能无中生有。 使用 kubeflow/tf-operator 执行分布式 TensorFlow 作业, 模型迭代必须等待申请的进程全部启动后才能开始。 如果集群资源不足以启动所有进程,则当前作业只能等待其他作业释放资源。 为了缩短资源等待时间,可以给作业配置专有资源池。由于资源不共享, 集群资源利用率会很低。所以 kubeflow/tf-operator 很难同时兼顾研发效率和集群利用率。
ElasticDL 利用 TensorFlow eager execution 和 Kubernetes API, 只要部分进程启动就可以开始模型迭代,无需等待所有进程全部启动。 当集群中有其他作业释放资源时,可以启动新的进程加入到训练作业中, 加速模型迭代。这样既能缩短用户作业等待时间,也能提升集群资源利用率。
基于 TensorFlow Eager Execution 实现分布式训练
目前基于 TensorFlow 的分布式训练系统大致可以分为以下四类:
| TensorFlow 1.x graph mode | TensorFlow 2.x eager execution | |
|---|---|---|
| in TensorFlow runtime | TensorFlow’s parameter server | TensorFlow distributed strategy |
| above TensorFlow API | Horovod | ElasticDL, Horovod |
如上文解释,我们没法通过修改 TensorFlow runtime 实现完备的主动的容错和弹性调度。 ElasticDL 和 Horovod 都是在 TensorFlow API 基础上构建。 ElasticDL 位于田字格的右下角,是为了利用 Kubernetes 来实现容错和弹性调度。
一个 Horovod 作业的每个进程调用单机版 TensorFlow 做本地计算, 然后收集 gradients,并且通过 AllReduce 调用汇聚 gradients 并且更新模型。 在 TensorFlow 1.x graph mode 下,深度学习计算是表示成一个计算图(graph), 并且由 TensorFlow runtime 解释执行。 Horovod 通过包裹 Optimizer 的方式添加对 gradient 的 AllReduce 调用。 TensorFlow 2.x eager mode 采用和解释执行图完全不同的深度学习计算方式。 前向计算过程把对基本计算单元(operator)的调用记录在一个内存数据结构 tape 里, 随后反向计算过程(计算 gradients)可以回溯这个 tape, 以此调用 operator 对应的 gradient operator。 Horovod 通过包裹 tape 完成 AllReduce 调用。 Horovod 和 TensorFlow 一样,不是 Kubernetes-native,所以它提供的 AllReduce 操作不支持容错和弹性调度。 这一点和 ElasticDL 不一样。 ElasticDL 通过 tape 获取 gradient 后,可以使用 Parameter Server 或者 AllReduce 分布式策略来更新模型参数。 并且,ElasticDL 作为 kubernetes-native 的分布式系统,可以通过调用 Kubernetes API 来支持容错和弹性调度。
Kubernetes-native 的弹性调度
ElasticDL 通过实现一个 Kubernetes-native 的框架,调用 TensorFlow 2.x 来实现弹性深度学习训练。所谓 Kubernetes-native 指的是一个程序调用 Kubernetes API 来起止进程。ElasticDL 没有选择开发 Kubernetes Operator, 是因为 Operator 只能管理作业集群状态。像上面所说的, 如果训练框架自身不支持容错和动态增加进程数,Operator 也无能为力。 所以 ElasticDL 通过在 Kubernetes 上创建 master 进程来控制深度学习训练作业的弹性调度。
ElasticDL 的 master 会根据数据索引将数据分片,为每个数据分片创建一个 task。 然后 master 会调用 Kubernetes API 启动多个 worker 进程。每个 worker 启动后, 会向 master 请求 task。worker 收到来自 master 分发的 task 后, 会读取 task 对应的数据分片来前向计算和梯度计算。
同时,master 会通过 Kubernetes API 监听集群中每个 worker 的状态。 当有 worker 被高优先级作业抢占后,master 会回收该 worker 的未完成 task, 然后重新分发给其他的 worker。同时 master 会尝试通过 Kubernetes API 重新拉起被抢占的 worker。等到资源充足时,worker 进程会被重新启动, 并加入训练作业。
Kubernetes-native 架构使得 master 进程有机会与 Kubernetes 协作实现容错和弹性调度。不过,因为 ElasticDL 调用 Kubernetes API, 也就意味着 ElasticDL 只能运行在 Kubernetes 上。
理论上,不调用 Kubernetes API 也是可以实现一定程度的容错的。 即使没有 Kubernetes 的通知,master 可以通过检查其他进程的心跳(heartbeat) 或者检查 TCP 连接状态,判断其他进程的生死存亡。 但是,不调用 Kubernetes API(或者其他调度系统的 API), master 无法通知调度系统重启进程,也无法得知新启动的进程的信息, 并且帮助它加入作业。这种“非 Kubernetes-native”的容错方式颇为被动, 只能接受资源紧张时一些进程被抢占而挂掉的事实, 而不能在其他作业释放资源后增加进程充分利用空闲资源。
弹性调度 Benchmark
为了说明 ElasticDL 弹性调度可以带来用户体验和集群利用率的双丰收,我们做了三个 实验来对比弹性调度和无弹性调度的性能。
实验一:多个深度学习训练作业同时在集群上启动
考虑两个深度学习训练作业需要的资源总和略超过集群的情况:
- 如果没有弹性调度,第二个作业需要等待第一个作业完成后才能启动。 第二个作业的发起人需要等很久 —— 用户体验不好。 并且任何时刻只有一个作业在运行 —— 集群资源用不满。
- 如果有弹性调度,则两个作业并发执行,虽然后启动的作业拿不到期待的全部资源, 但是也马上就开始执行了 —— 用户体验好。因为两个作业并发 —— 集群被用满。
我们做了一个实验来验证上述好处,这个实验可以在蚂蚁金服的 Kubernetes 集群(ASI) 和开源 Kubernetes 集群上复现。
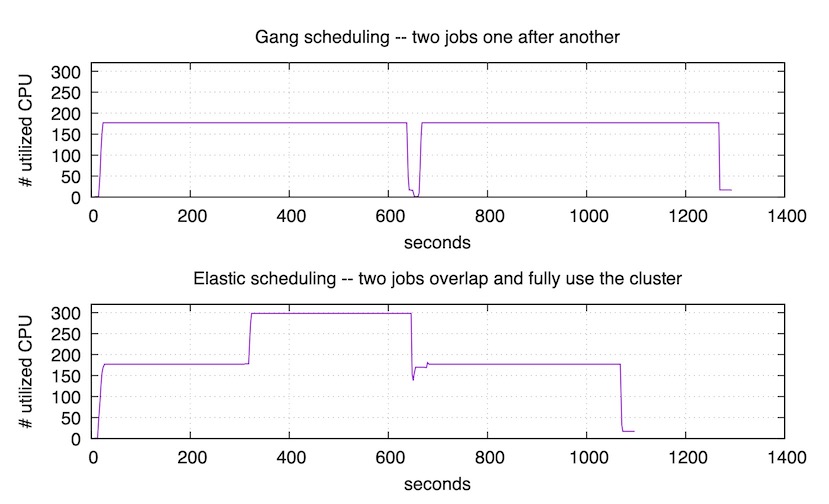
上图对应的实验里,我们用 kubeflow/tf-operator 提交了两个训练作业, 每个作业都需要 175 个 CPU。而集群总 CPU 数是 320,不足以同时运行两个作业, 所以依次运行它们。可以看到第一个作业在 650 秒时结束。随后集群花了一点时间调度, 然后开始运行第二个作业,直到 1300 秒时结束。
下图对应的实验里,我们用 ElasticDL 来执行同样的两个训练作业。 第一个作业提交之后的 300 秒,我们提交了第二个作业。 第二个作业⻢上就开始运行,用满了集群剩下的资源,而不需要等到 第一个作业结束。 在 650 秒时,第一个作业结束。随后,在 1100 秒时,第二个作业也结束了。 因为弹性调度,使得两个作业尽量同时运行,所以总结束时间比也上图要早。
总结:
- 用户等待作业启动时间几乎是 0。这对于深度学习很重要, 因为用户最关注的是第一个迭代能否执行成功,如果失败了,能够快速发现用户程序的 bug。
- 集群利用率高。第二个弹性调度实验执行期间,有一段时间集群利用率是 100%; 其他时间也不低于第一个无弹性调度实验。
- 作业完成更快。第二个试验里,两个作业用了约 1100 秒; 第一个实验里需要约 1300 秒。
实验二:深度学习训练作业和在线服务混布
运行各种在线服务的生产集群,通常需要留出余量资源,以应付突然增⻓的用户请求量。 我们希望利用这些“余量”来做深度学习训练,从而提升集群利用率。
下面实验验证:通过用较低优先级运行 ElasticDL 训练作业,在用户请求增加的时候,
Kubernetes 自动扩容在线服务(nginx);此时 ElasticDL 作业自动释放资源,
配合在线服务的扩容。当流量高峰过去之后,Kubernetes 自动缩容 nginx 服务,
此时,ElasticDL 自动利用释放的资源来扩容训练任务。
真实场景中,可以在 Kubernetes 上使用 Horizontal Pod Autoscaler
根据流量的大小来对在线服务进行伸缩。在本实验中,则是通过在特定的时间点,
调用 kubectl scale 命令直接对在线服务进行伸缩,来去模拟流量的增加或者减少。
集群中总共有 320个CPU,训练任务是 deepFM 二分类模型训练,运行时长约40分钟。
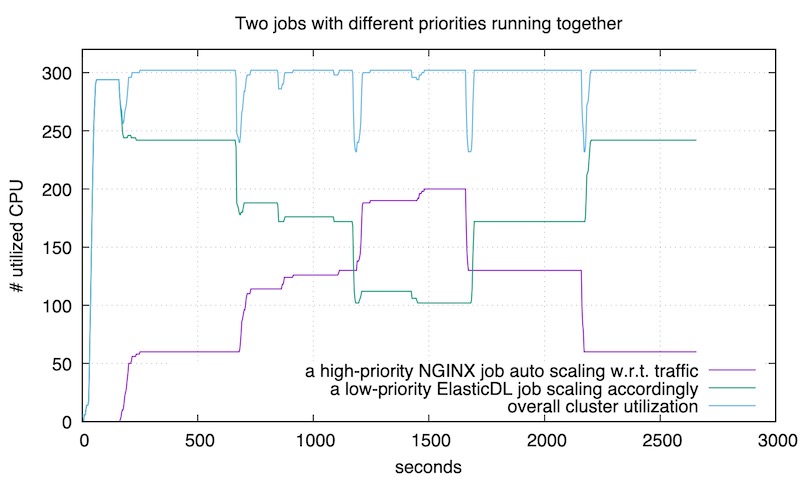
图中紫色曲线是 nginx 服务使用的 CPU 数量,随用户请求数量变化。 绿色曲线是 ElasticDL 训练作业使用的 CPU 数量,随 nginx 的资源需求自动变化。 蓝色曲线是机群的总体资源利用率 —— 保持在 90% 以上。
实验三:训练时调整 Worker 数量不影响收敛性
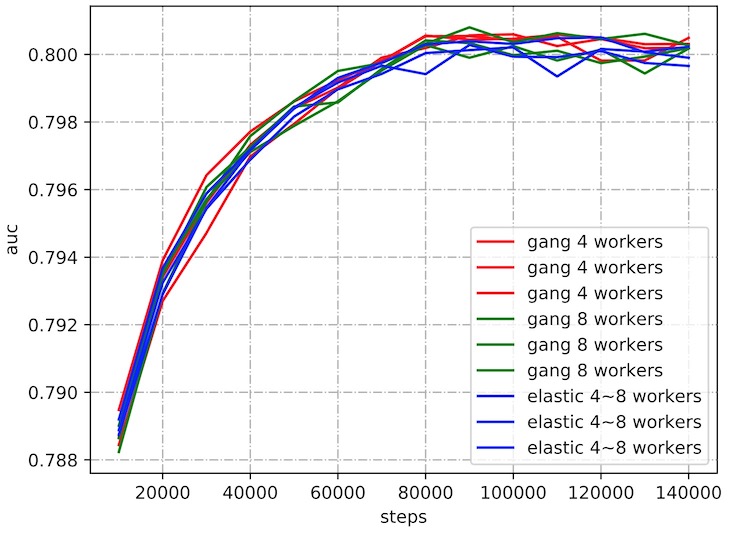
有用户担心训练过程中 worker 的数量发生变化,会导致模型不收敛。 实际情况下并未发生这类问题。使用 Kaggle Display Advertising Challenge 的数据集,其中训练样本 4 千万条,测试样本 600 万条。 用 ElasticDL 和用无弹性调度的 kubeflow/tf-operator 分别 训练 wide & deep 模型。模型中 deep 包含 2 层 layer,输出单元数分别为 8 和 4,激活函数才用 relu,模型收敛曲线如下:
ElasticDL 在蚂蚁金服花呗推荐场景的实践
蚂蚁金服部署了万级节点的 Kubernetes 集群, 同时蚂蚁金服有许多场景使用深度学习来提升产品性能和用户体验 算法工程师们共用一个 Kubernetes集群来训深度学习模型。 ElasticDL 已经成功将蚂蚁花呗推荐场景的深度学习模型运行在 Kubernetes 集群上。
蚂蚁花呗是蚂蚁金服推出的一款消费信贷产品。用户在购买商品时, 会给用户推荐花呗支付,并给予一定额度的优惠。 此推荐场景使用的是 Deep Interest Evolution Network (DIEN) 来预估推荐的点击率。DIEN 模型的输入包括用户属性特征、 商品属性特征和用户行为的序列特征,其中用户和商品属性特征是高维稀疏特征。 所以模型首先需要通过 embedding 将稀疏特征转成 embedding vector, 然后进行给深度学习模型进行计算。因为 embedding 的规模很大, ElasticDL 采用 Parameter Server(PS)策略来进行分布式训练, 将参数分散到多个 PS 节点上,worker 负责前向计算并获取梯度, PS 负责梯度汇总和参数更新。
模型上线后,我们和使用 TensorFlow 原生分布式训练的模型进行了对比, 线上点击率持平。同时在一个 Kubernetes namespace 下运行多个训练任务时, 可以占满该 namespace 下的资源。